from tlp.data import DataLoader
import re
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
Markovian Shakespeare#
The Pattern#
patt = re.compile(
"(?:\A|\n\n)" # beginning of file or two newlines
"(^[A-Z][\w ]+):$" # capital start, colon end
"\n([\s\S]+?)" # ANYTHING, but lazy
"(?=\n\n|\Z)", # until you hit two newlines or end-of-file
flags=re.M
)
The Data#
df = (DataLoader.tiny_shakespeare()
|> patt.findall
|> pd.DataFrame.from_records$(columns=['speaker', 'dialogue'])
|> .rename_axis(index='line')
)
df
| speaker | dialogue | |
|---|---|---|
| line | ||
| 0 | First Citizen | Before we proceed any further, hear me speak. |
| 1 | All | Speak, speak. |
| 2 | First Citizen | You are all resolved rather to die than to fam... |
| 3 | All | Resolved. resolved. |
| 4 | First Citizen | First, you know Caius Marcius is chief enemy t... |
| ... | ... | ... |
| 7102 | ANTONIO | Nor I; my spirits are nimble.\nThey fell toget... |
| 7103 | SEBASTIAN | What, art thou waking? |
| 7104 | ANTONIO | Do you not hear me speak? |
| 7105 | SEBASTIAN | I do; and surely\nIt is a sleepy language and ... |
| 7106 | ANTONIO | Noble Sebastian,\nThou let'st thy fortune slee... |
7107 rows × 2 columns
“Importance”?#
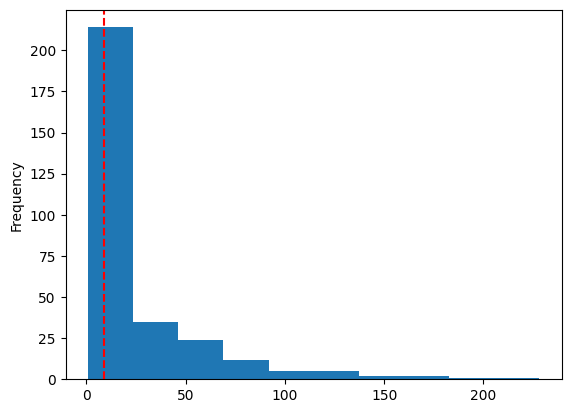
Speaker Frequency?#
df.speaker.value_counts().plot.hist()
plt.axvline(df.speaker.value_counts().median(), color='r', ls='--')
print('median lines', df.speaker.value_counts().median())
median lines
9.0
df.speaker.value_counts()
speaker
GLOUCESTER 228
DUKE VINCENTIO 191
MENENIUS 162
ROMEO 162
PETRUCHIO 157
...
Players 1
All The People 1
ALL 1
GARDENER 1
FRANCISCO 1
Name: count, Length: 301, dtype: int64
df.dialogue.str.lower().str.findall(r'\b(\w\w+)\b').explode().value_counts()
dialogue
the 6285
and 5690
to 4934
of 3541
you 3211
...
blades 1
spanish 1
ambuscadoes 1
breaches 1
eyelids 1
Name: count, Length: 11421, dtype: int64
Markov Model#
import pomegranate as pg
model = (df.dialogue.str.lower()#.str.findall(r'\b(\w\w+)\b')
|> .tolist()
|> pg.MarkovChain.from_samples$(k=3)
)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[7], line 1
----> 1 import pomegranate as pg #1: import pomegranate as pg
2 model = ((pg.MarkovChain.from_samples)((df.dialogue.str.lower()).tolist(), k=3)) #.str.findall(r'\b(\w\w+)\b') #2: model = (df.dialogue.str.lower()#.str.findall(r'\b(\w\w+)\b')
ModuleNotFoundError: No module named 'pomegranate'
for i in range(5):
model.sample(100)|> ''.join |> print$('\n---\n')
model.distributions[0].keys()|> ', '.join |> print
# model.distributions[1]
def ecdf(x):
x = np.sort(x)
n = len(x)
def _ecdf(v):
# side='right' because we want Pr(x <= v)
return (np.searchsorted(x, v, side='right') + 1) / n
return _ecdf
def ecdf_tf(s):
return ecdf(s)(s)
df_prob = (df
.assign(logprob=df -> df.dialogue.str.lower().apply(model.log_probability))
.assign(mean_prob=df -> df['logprob']/df.dialogue.str.len())
.assign(rarity=df -> ecdf_tf(-df['mean_prob']))
.assign(importance=df -> df['rarity']*ecdf_tf(df.groupby('speaker').speaker.transform('count')))
)
df_prob
def get_stat_order(df, colname, topn=50):
return (
df[df.speaker.isin(common_speakers)]
.groupby('speaker')[colname]
.median().sort_values(ascending=False)
.index.tolist()
) where:
common_speakers = (
df.speaker.value_counts()
|> s-> s[s>=50]
|> .index.tolist()
)
sns.catplot(
data=df_prob,
y='speaker', x='rarity', kind='box',
orient='h', height=10, aspect=.5, color='grey',
order=get_stat_order(df_prob, 'rarity')
)
sns.catplot(
data=df_prob,
y='speaker', x='importance', kind='box',
orient='h', height=10, aspect=.5, color='grey',
order=get_stat_order(df_prob, 'importance')
)